Na Agencijo za energijo (v vlogi regulatorja), ELES (v vlogi sistemskega operaterja električnega omrežja), moje elektrodistribucijsko podjetje ter izbranemu dobavitelju sem poslal dopis o ničnosti obračunavanja presežne moči.
Ključni težavi sta dve, prva je obveza plačevanja kazni in nezmožnost izbire drugačnega načina uveljavljanja dogovorjene moči, druga pa nerazumno dolg rok za upoštevanje nove dogovorjene moči.
Dopis:
Zadeva: Ničnost obračunavanja presežne moči
Spoštovani,
Ob začetku uporabe novega omrežninskega sistema vas opozarjam, da smatram morebitno presežno moč kot pogodbeno kazen s katero nisem izrecno soglašal, ter kot tako nično v skladu z Zakonom o varstvu potrošnikov (ZVPot-1).
ZVPot-1 v 1. odstavku 23. člena določa, da se pogodbeni pogoji štejejo za nepoštene, če »v škodo potrošnika povzročijo znatno neravnotežje v pogodbenih pravicah in obveznostih strank« ali »povzročijo, da je izpolnitev pogodbe neutemeljeno v škodo potrošnika« ali »povzročijo, da je izpolnitev pogodbe znatno drugačna od tistega, kar je potrošnik utemeljeno pričakoval« ali »nasprotujejo načelu poštenja in vestnosti«.
Nedvomno je v primeru obračunavanja presežne moči izpolnitev pogodbe znatno drugačna od tega, kar potrošnik pričakuje, saj se obračunava vsako 15-minutno obdobje preseganja moči. Ob večjem številu večjih preseganj moči lahko obračunana presežna moč mesečno predstavlja večji strošek kot dogovorjena moč.
Presežna moč ima kaznovalno naravo. Namen obračunavanja presežne moči je, da je odjemalcu v finančnem interesu, da dogovorjeno moč postavi dovolj visoko, da ne prihaja do pogostega obračunavanja presežne moči. Plačevanje presežne moči je zato možno razumeti tudi kot pogodbeno kazen v korist podjetja.
Pogodbena kazen je v 8. alineji 4. odstavka 23. člena ZVPot-1 opredeljena kot nepošten pogodbeni pogoj. S 24. členom ZVPot-1 so nepošteni pogodbeni pogoji prepovedani in nični.
Obračunavanje presežne moč je možno razumeti tudi kot dodatno dogovorjeno plačilo, ki po 25. členu ZVPot-1 potrebuje izrecno soglasje potrošnika. Od mene soglasja za plačevanje presežne moči ni prejel nihče, niti Elektro Ljubljana, niti ELES, niti Agencija za energijo.
Priznam, da je omrežnina nekoliko poseben primer, saj višino omrežnine določa Agencija za energijo, upravičenci pa so akterji na elektroenergetskem področju, predvsem elektro distribucijska podjetja, sistemski operater omrežij ter Agencija za energijo. Elektro distribucijska podjetja imajo naravni monopol, plačevanje omrežnine pa je urejeno s predpisom in uporabniki sistema nimamo tržne izbire.
Navedene okoliščine ne spreminjajo dejstva, da je bilo za zaščito potrošnikov v Aktu o metodologiji za obračunavanje omrežnine za elektrooperaterje (v nadaljevanju Akt), ki se je začel uporabljati s 1. oktobrom 2024, pomanjkljivo poskrbljeno. Da vidik uporabnikov sistema na novo metodologijo omrežnine ni bil znatno upoštevan pričajo tudi poročila ob javnem posvetovanju »Prenova metodologije obračuna omrežnine in tarifnega sistema«, kjer je bil na delavnicah prisoten zgolj en posameznik kot fizična oseba in en predstavnik potrošniške organizacije. Ni videti, da bi bile opravljene druge analize glede učinkov prenove omrežnine na uporabnike sistema – fizične osebe.
Pri pogodbi o dobavi Zakon o oskrbi z električno energijo (ZOEE) gospodinjstvom in malim poslovnim odjemalcem priznava šibkejši status in jim v 16. členu dodeljuje dodatne pogodbene pravice, v 33. členu pa ureja tudi ranljive odjemalce. ZOEE določa, da se mora zamenjava dobavitelja zgoditi v roku 24 ur od popolne vloge.
Za pogodbo o uporabi sistema podobnih določil ZOEE nima. Akt o omrežnini je kot edini način uveljavljanja pogodbenih določil oz. dogovorjene moči predvidel obvezo plačila presežne moči - kazni in ne dopušča drugačnih možnosti, pri tem pa se ne ozira na kategorijo ali socialni status uporabnika sistema. Ob morebitnem zavedanju, da je raba moči višja od pričakovane pa mora uporabnik sistema na spremembo dogovorjene moči čakati nerazumno dolgo - od 21 do 53 dni. V času od obvestila elektro distribucijskega podjetja in preden začne spremenjena dogovorjena moč učinkovati, je plačevanje presežne moči še vedno v veljavi.
Velja tudi omeniti, da mi kot uporabniku sistema ni dano orodje, s katerim bi lahko nadzoroval sprotno porabo ter s tem zagotavljal izpolnitev pogodbenih obveznosti, torej odjem znotraj dogovorjene moči.
V kolikor v danem primeru zavračate pristojnost ZVPot-1, Obligacijski zakonik v 247. členu določa, da se upnik in dolžnik lahko dogovorita o pogodbeni kazni. Dogovor zahteva obojestransko soglasje in ne vsiljevanje s strani močnejše stranke, kar je v tem primeru brez dvoma javna agencija kot regulatorni organ, ki sprejema obvezujoče predpise.
S spoštovanjem,
Ministrstvo za okolje, podnebje in energijo bo prvič v Sloveniji subvencioniralo električna kolesa. Pričakujem, da bo ta razpis med bolj izkoriščenimi. Uporaba dvokoles, tudi električnih, je en boljših načinov za zniževanje ogljičnega odtisa.
Kaj je tako čudežnega pri kolesih? Kolesa izmed vseh načinov gibanja po prostoru potrebujejo najmanj energije na prevoženo razdaljo. Kolesa so najbolj učinkovit mehanizem za gibanje po tleh, vključno s celotnim živalskim svetom.
Z elektrifikacijo koles se do neke mere poveča potreba po električni energiji, a precej manj, kot v primeru električnega avta. Električna kolesa trošijo do približno 16Wh na kilometer v primeru vožnje zgolj na električni pogon in 10Wh na kilometer v primeru pomožnega električnega pogona. Električni skuterji trošijo tja do 40Wh na kilometer. Manjši električni avtomobil troši do 200Wh na kilometer. Električno kolo za premagovanje razdalje torej porablja 10x do 20x manj energije kot električni avto. V primerjavi z avtomobilom na fosilna goriva, ki troši 6 litrov na 100 prevoženih kilometrov, je električno kolo kar 30x do 60x bolj učinkovito.
Posledično električni dvo- in trocikli trenutno prispevajo največji delež k zniževanju povpraševanja po naftnih derivatih, kot kaže spodnji graf.
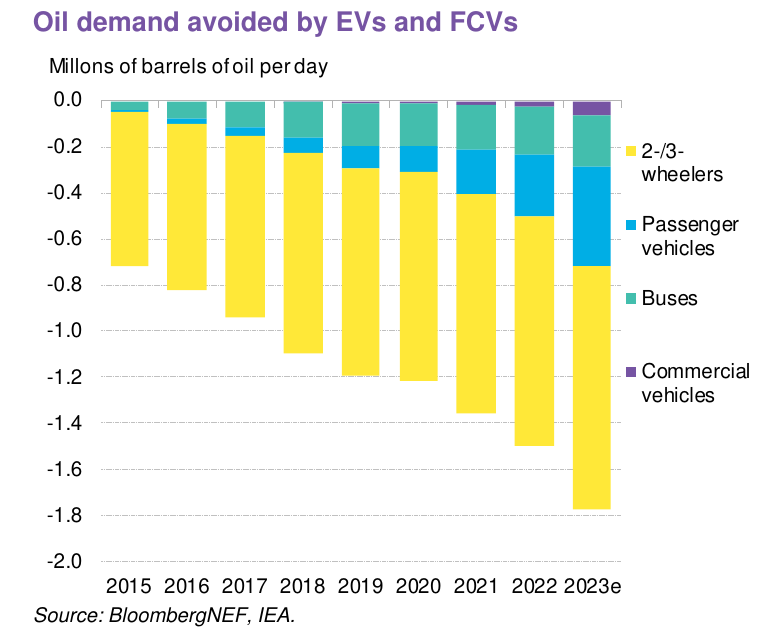
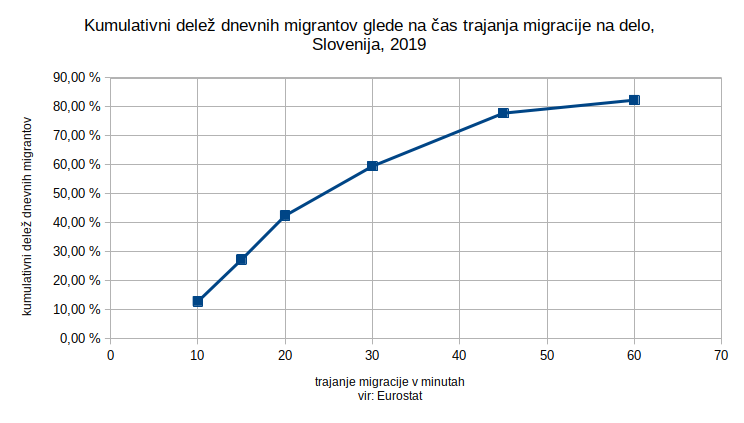
Kar 59 odstotkov dnevnih migracij v Sloveniji traja manj kot pol ure, povprečna migracija traja 23 minut. Ob predpostavki, da je večini ljudi sprejemljivo do pol ure dnevne migracije do delovnega mesta, je razdalja, ki jo opravi električno kolo s hitrostjo 30km/h, približno 15 kilometrov. Znotraj razdalje 15 kilometrov od centra Ljubljane so Medvode, Mengeš, Domžale, Škofljica in Ig.
Nekaterim elektrifikacija koles ni dobrodošla in so mnenja, da morajo biti kolesa zgolj na nožni pogon. Na zgoraj omenjenih relacijah trenutno kolesari zelo zelo malo ljudi. Ni se za bati, da bi število kolesarjev iz teh krajev zrastlo, če jim ponudimo navadno kolo. Vožnja z električnim kolesom pa dopušča dneve, ko nismo v najboljši kondiciji in razdalje, na katerih bi se sicer prepotili.
Seveda k kolesarjenju na daljše razdalje pripomore tudi dobra kolesarska infrastruktura. Žal je ta pri nas slabša kot za osebna vozila. Stanje se izboljšuje, ampak počasi. Morda je največja ovira za električno kolesarjenje pomanjkanje varnih kolesarnic.
Subvencioniranje nakupov je pogosto stvar polemik. Na Švedskem so že uvedli podoben ukrep, za katerega obstaja ekonomska analiza o učinkih ukrepa. Avtorji so ugotovili, da je kar 23% oz. približno četrtina kupcev električnih koles povsem opustilo rabo avtomobila za dnevno migracijo, več kot pol (54%) pa jih je zmanjšalo rabo osebnega avtomobila. Subvencija ni bila vezana na lastništvo osebnega avtomobila, tako da je bilo kar nekaj takih kupcev, ki z električnim kolesom niso nadomeščali rabe avtomobila. Posledično so, s precej predpostavkami, izračunali, da tak netargetiran program subvencije vrednoti emisije z 589 USD na tono emisij CO2. Vredno razmisliti, če ne bi bilo bolje, da subvencija cilja neposredno na obstoječe lastnike avtomobilov.
Viri:
- Država bo prvič subvencionirala električna kolesa, Forbes
- How far can an electric bicycle really go on a single charge, Electrek
- Majority commuted less than 30 minutes in 2019, Eurostat
- Energy efficiency in transport, Wikipedia
- Odprtje kolesarske povezave Kamnik-Mengeš-Trzin-Ljubljana, Občina Kamnik
- Welfare Implications of Electric-Bike Subsidies: Evidence from Sweden
Vodik se ponuja kot ena izmed rešitev za nekatere energetske nizkoogljične izzive. Sledi kratek pregled izzivov z rokovanjem vodika.
Najprej je pomembno, da razumemo, da vodik kot ga pojmujemo danes, ni vir energije. Vir energije se nahaja v naravi, vloga vodika pa se pojavlja predvsem kot shramba energije. Vir nam daje energijo, npr. sončna elektrarna, zatem to električno energijo pretvorimo v vodik, ki učinkuje kot shramba. Obstajajo sicer indici, da se vodik pojavlja tudi v naravi, a se pojavlja na drugačnih lokacijah kot nafta in fosilni plin. Ker ga nismo iskali, ga do sedaj nismo našli.
Tehnični izzivi vodika
Vodik je vnetljiv. To je precej pomembna lastnost, saj na sproščanju energije pri gorenju temelji pridobivanje energije iz vodika.
Vodik je plin brez vonja in barve. Ker je brez vonja in barve, obstaja nevarnost zadušitve zaradi pomanjkanja kisika, ki ga lahko vodik potencialno izpodrine v zaprtih prostorih. Zaželeno je, da se z vodikom operira na dobro prezračevanih lokacijah.
Smiselno bi bilo, da se vodiku primeša marker, kot to delamo z metanom, oz. naftnim plinom. Težava je, da so zlasti gorivne celice precej občutljive na druge primesi, ki zmanjšujejo učinkovitost in življenjsko dobo celic.
Precej večja nevarnost kot zadušitev je gorenje. Za vžig vodika je potrebna precej nizka aktivacijska energija, približno 20x manjša kot pri metanu ali pri bencinu. Oba smo še vedno uspeli do neke mere zaobvladati, čeprav ne brez nesreč.
Vodik je eksploziven v zelo širokem pasu v zmesi s kisikom, v koncentracijah med 4 in 74% volumenskega deleža. Za primerjavo - metan, ki je poglavitna sestavina zemeljskega plina, je eksploziven v koncentracijah med 5% in 15%. Zunaj eksplozivnega območja gori, a ne eksplodira.
Plamen vodika je slabo opazen. Nima intenzivne barve oz. je rahlo svetlo moder, ter je ob dnevni svetlobi za človeško oko neopazen. Plamen vodika tudi ne seva močno v infrardečem spektru, tako da lahko človek stoji poleg plamena vodika, pa se tega sploh ne zaveda. Če nekdo stopi v plamen vodika, nepodučenemu opazovalcu ne bo jasno, da se je človek vžgal.
Vodik ima velik volumen. Energija na kilogram mase oz. specifična energija je za vodik precej velika, kar 120 MJ/kg. Težava je, da ima 1kg vodika v primerjavi z drugimi energenti zelo velik volumen. Za doseganje boljše volumetrične gostote ga je potrebno bodisi stiskati bodisi utekočiniti. Raziskave potekajo tudi v smeri iskanja materiala, ki bi omogočal vezavo večjih količin vodika ter s tem omogočil hrambo vodika.
Vodik se utekočinja pri 20K oz. pri -253°C, kar je zelo nizka temperatura. Za doseganje tako nizke temperature je potrebno veliko energije, kar dela postopek utekočinjanja energetsko potraten. S segrevanjem se vodik uplinja in s tem viša tlak v rezervoarju. Da tlak ne preseže tehničnih omejitev posode, v kateri je vodik, je potrebno presežno uplinjen vodik bodisi nadzorovano izpuščati skozi varnostni ventil, bodisi je potrebno uplinjen vodik ponovno ohladiti in utekočinjati.
Vodik glede na spin elektronov obstaja v dveh stanjih, orto-vodik, kjer je spin elektronov pri obeh atomih v isto smer, in para-vodik, kjer je spin elektronov v različno smer. Pri sobni temperaturi je ravnovesno razmerje med orto in para vodikom 3:1. Pri temperaturah, pri katerih se vodik utekočinja, pa je razmerje precej bolj v prid para-vodiku. S časom se utekočinjen orto-vodik pretvarja v para-vodik. Težava je, da se pri pretvorbi iz orto v paravodik sprošča toplota, ki je dovoljšnja, da bi lahko uplinila ves utekočinjen vodik.
Uplinjanje tekočega vodika predstavlja velik problem za trajnejšo hrambo. BMW je izdelal osebno vozilo Hydrogen 7, kateremu se zaradi izparevanja vodika poln rezervoar izprazni v 10 do 12 dneh. Zaradi potencialnega uhajanja vodika tako vozilo ne sme biti parkirano v zaprtem prostoru. Večina novejših osebnih vozil ima zato rezervoar z vodikom, stisnjenim na 700 bar, kjer problema z izparevanjem ni.
Vodik se segreva, ko se razteza. Črpanje vodika v rezervoar vozila je prečrpavanje vodika iz rezervoarja z višjim tlakom (polnilna postaja) v rezervoar z nižjim tlakom (vozilo). Pri tem se zaradi raztezanja sprošča toplota, problem pa postane večji pri večjih volumnih rezervoarja vozila. To povečuje tveganje za vžig oz. eksplozijo.
V vozilih na vodikov pogon se danes večinoma uporablja stisnjen vodik pri 350 barih oz. 700 barih tlaka. Pri polnjenju z višjim tlakom se vodik pred črpanjem v vozilo predhodno ohladi, da se izniči efekte segrevanja pri raztezanju vodika, zato v raznih demonstracijah polnjenja večjih vozil pogosto vidite kako operater priklaplja polnilno cev za vodik v zelo debelih toplotno izolativnih rokavicah, da ne utrpi ozeblin.
Rezervoar za vodik mora biti sposoben prenašati večje raztezne obremenitve. Kljub tem izzivom gre razvoj naprej in so rezervoarji sposobni opraviti tudi 5500 ciklov polnjenja in praznenja. Tak rezervoar bi ob vsakodnevnem polnjenju in praznenju zadostoval za 15 let, zato lahko mirno rečemo, da bi ob odsotnosti drugih faktorjev rezervoar zadostoval za življenjsko dobo vozila.
Vodik je ena izmed najmanjših molekul. Je tako majhna, da je sposobna vdreti v strukturo marsikaterega materiala. S kovinami rad tvori hidride, pri tem pa poveča krhkost materiala. Posebej rado se to dogaja na mestih, kjer prihaja do mehanskih napetosti, npr. pri zvarih. Zaradi tega bo pri morebitnem prehodu na višji delež vodika v plinovodih še kar nekaj težav, saj se zna zgoditi, da bo prihajalo do poškodb na plinovodih, če ti ne bodo ustrezno nadgrajeni.
Ker je vodik ena od najmanjših molekul, lahko prodre skozi marsikateri material. Znana je epizoda, ko je uhajanje večjih količin helija povzročilo nedelovanje mobilnih telefonov iPhone, ker je helij prodrl v mikro-elektromehanski čip, ki je skrbel za delovanje frekvence električne naprave. Helij je žlahten element in ne reagira z drugimi materiali, vodik pa je zelo reaktiven in je večja možnost, da naprave tudi trajno poškoduje.
Vodik ima toplogredni učinek. Vodik sam ni toplogredni plin, njegov toplogredni prispevek pa nastane predvsem s podaljšanjem življenjske dobe metana v zraku. Hidroksilni radikal (OH-), ki bi se sicer vezal z metanom, se v tem primeru veže z vodikom, s tem pa metan dlje ostane v atmosferi. Toplogredni učinek vodika je ocenjen na 11x CO2e na 100 let.
Pridobivanje vodika je energetsko potratno. Shranjevanje električne energije v baterije ter uporaba energije iz baterije dosega učinkovitost cikla med 70% in 95%. Izdelava vodika in pridobivanje električne energije dosega učinkovitost 54%, kar je približno polovico učinkovitosti, ki jo dosegajo baterije.
V kolikor bi vodik uporabljali za zgorevanje, je učinkovitost še nižja in razen v izjemnih situacijah ni komercialno zanimiva.
Poglavitna nevarnost vodika
Poglavitna nevarnost vodika je ogenj in eksplozija. Vodik je lahko vnetljiv in eksploziven na širokem področju koncentracij. Je brez vonja, barve ali okusa. Molekula vodika je majhna in lažje pušča skozi membrane.
Utekočinjen vodik predstavlja še hujši tehnični zalogaj, saj je potrebno poleg zagotavljanja tesnosti skrbeti še za toplotno izolacijo vseh vodov, po katerih se pretaka vodik. V primeru, da tesnenja ni, se namreč znotraj vodov začne vodik uplinjati, problemi pa nastajajo tudi na zunanjih vodih, saj ima tekoči vodik tako nizko temperaturo, da se utekočinja zrak, ki pride v stik z vodom.
Ker se kisik utekočinja pri višji temperaturi kot dušik, pride do tega, da z voda kaplja utekočinjen kisik. Če utekočinjen kisik kapne na kar koli gorljivega, je precej visoka verjetnost, da snov zagori.
Nevarnost, ki jo predstavlja vodik, je zato precej bolj obsežna kot pa smo je navajeni iz drugih goriv.
Izvor vodika
Vodik se praviloma smatra kot shramba energije, ne kot vir. Večina danes porabljenega vodika namreč pride iz pretvorbe drugih surovin, pogosto iz metana ali vode. Da se je ljudem lažje pogovarjati, so se ljudje izmislili poimenovati vodik po barvah glede na vir energije in surovine za proizvodnjo vodika. Vodik kot plin fizikalno gledano nima barve, gre zgolj za poimenovanje.
Sivi vodik je iz zemeljskega plina, pri čemer se CO2 izpusti v ozračje. To predstavlja večino danes komercialno proizvedenega vodika.
Črni vodik je iz premoga.
Modri vodik je iz zemeljskega plina, pri čemer se stranski proizvod CO2 zajame in shrani.
Zeleni vodik je iz obnovljivih virov energije in je nekako najbolj zaželen, če se želimo izogniti hujšim posledicam toplogrednega efekta.
Roza ali rdeči vodik, ki se ga proizvaja s pomočjo jedrske energije, kjer se koristno uporablja tudi toploto jedrske reakcije.
Rjavi vodik, ki se pridobiva iz biomase.
Rumeni vodik, ki se ga proizvaja iz mešanice elektike, ki je na omrežju.
Beli vodik je vodik, ki se že v naravi pojavlja kot vodik in je edini izvor vodika, za katerega lahko rečemo, da je vir energije. Do nedavnega nismo vedeli, da se vodik pojavlja tudi elementarno v naravi v večjih količinah. V Franciji so v stari vrtini našli presenetljivo visoke koncentracije vodika.
Povezave:
- Hidden hydrogen, Science.org
- BMW's Hydrogen V12 Engine Is A Hilarious Engineering Stunt, Engineering Explained
- iPhones Are Allergic to Helium, ifixit
- For hydrogen to be a climate solution leaks must be tackled, Environmental Defense Fund
- Hydrogen 11 times worse than CO2 for climate, says new report
- The colour of hydrogen
- French drillers may have stumbled upon a mammoth hydrogen deposit, Ars Technica
- Hydrogen Compared with Other Fuels, Hydrogen Tools
- Safety Standard for Hydrogen and Hydrogen Systems, NASA (PDF)
- Hydrogen Safety, Wikipedia
- The Hype about Hydrogen
- Hydrogen Storage Challenges
- The Future of Hydrogen
Želel sem narediti hiter izračun emisij TGP zase iz energetske rabe. V osnovi večji del energije človek danes porabi za ogrevanje bivališča, ogrevanje sanitarne tople vode, elektriko, mobilnost. Poleg tega se emisije ustvarjajo tudi posredno, z nakupi hrane in drugih stvari in storitev, ampak človek v enem letu nakupi zelo veliko zelo različnih stvari in je to precej težje ovrednotiti ter presega cilj te objave.
Ogrevanje
Stanovanje se ogreva prek vročevoda Energetike Ljubljana. V stanovanju je števec, ki je za lansko leto odčital 2036 kWh porabe. Energetika Ljubljana je objavila, da je specifična emisija CO2 za vročo vodo v letu 2022 znašala 0,4727 kg CO2/kWh.
Sanitarna topla voda
Topla voda je prav tako vezana na vročevod. Letna poraba je bila 1644 kWh, specifična emisija CO2 je enaka kot zgoraj.
Elektrika
V letu 2022 je bilo na odjemnem mestu stanovanja porabljeno 1487 kWh električne energije. Za specifično emisijo CO2 za leto 2022 še ni podatka, tako da sem vzel vrednost za 2021, ki jo je naračunal IJS in upošteva tudi izgube na omrežju. Specifična emisija CO2 za leto 2021 znaša 0,316 kg CO2/kWh.
Mobilnost
Z bencinskim avtom sem lani tankal za 655 litrov bencina. Pri enem litru bencina nastane za 2,168 kg CO2 izpustov.
Emisije
| Področje | Količina | Specifična emisija CO2 | Skupne emisije |
|---|---|---|---|
| Ogrevanje stanovanja | 2.036 kWh | 0,4727 kg CO2e/kWh | 962 kg CO2e |
| Topla voda | 1.644 kWh | 0,4727 kg CO2e/kWh | 777 kg CO2e |
| Elektrika | 1.487 kWh | 0,316 kg CO2e/kWh | 470 kg CO2e |
| Mobilnost | 655 L bencina | 2,168 kg CO2e/L | 1420 kg CO2e |
Načina ogrevanja stanovanja ne morem spremeniti (niti to nima smisla), izolacija pa je vezana na izolacijo celotne stavbe, ki je skupinska investicija in zahteva svoj čas, voljo stanovalcev, finance in še kaj.
Topla voda je energetsko precej potratna, ampak vseeno se ne bi tuširal z ledenim tušem.
Električno omrežje je še večji sistem od lokalnega daljinskega ogrevanja in moramo pač zgraditi več nizkoogljičnih elektrarn. Za balkonsko elektrarno pa bi rabil balkon.
Največ emisij delam z avtomobilom, ki je poleg največje tudi najlažja priložnost za znižanje emisij, saj imam pri nakupu avtomobila povsem proste roke. Izziv pri električnem vozilu je polnjenje, saj za starejše bloke zopet ni enostavne rešitve za domačo polnilnico.
Faktorji emisij CO2 za Energetiko Ljubljana za leto 2022 (preden izginejo s spletne strani):
Specifična emisija t CO2 za 1 MWh vroče vode: 0,4727 tCO2/MWh
Specifična emisija t CO2 za 1 MWh tehnološke pare (parovod TE-TOL): 0,3994 tCO2/MWh
Specifična emisija t CO2 za 1 MWh tehnološke pare (parovod TOŠ): 0,2575 tCO2/MWh
V Sloveniji je položnica za električno energijo v osnovi razdeljena na tri dele: na energijo, ki je plačilo dobavitelju, na omrežnino, ki je plačilo operaterju distribucijskega in prenosnega sistema, ter davki, npr. trošarina in prispevek za obnovljive vire energije.
Omrežnina je bila do sedaj zelo predvidljiva. Plačuje se v obliki fiksnega in variablinega dela. Fiksni del je na kilovat glede na priključno moč, variabilni del pa je po porabljenih kilovatnih urah energije. Enake cene veljajo ne glede na razmere v omrežju in ne glede na to ali izkoriščate polno priključno moč ali samo del nje, in to ne glede na to kdaj se energija troši oz. z minimalno razliko med nižjo tarifo in višjo tarifo.
Po novem bo omrežnina nekoliko bolj razčlenjena. Cilj prenove omrežninskega sistema je, da se stroški omrežja bolje poravnajo s ceno, ki jo uporabniki omrežja plačujemo. Omrežje je najbolj obremenjeno ob viških, in viški porabe so tudi tisti dogodek, ki poganjajo investicije v omrežje.
Večina stvari je o omrežnini, ki stopi v veljavo s 1. julijem 2024, že znanega. Edina stvar, ki še manjka, so cene posameznih tarif, ki bodo verjetno določene bolj proti koncu leta, saj pred 1. julijem 2024 nimajo veljave.
Kaj torej vemo o omrežnini?
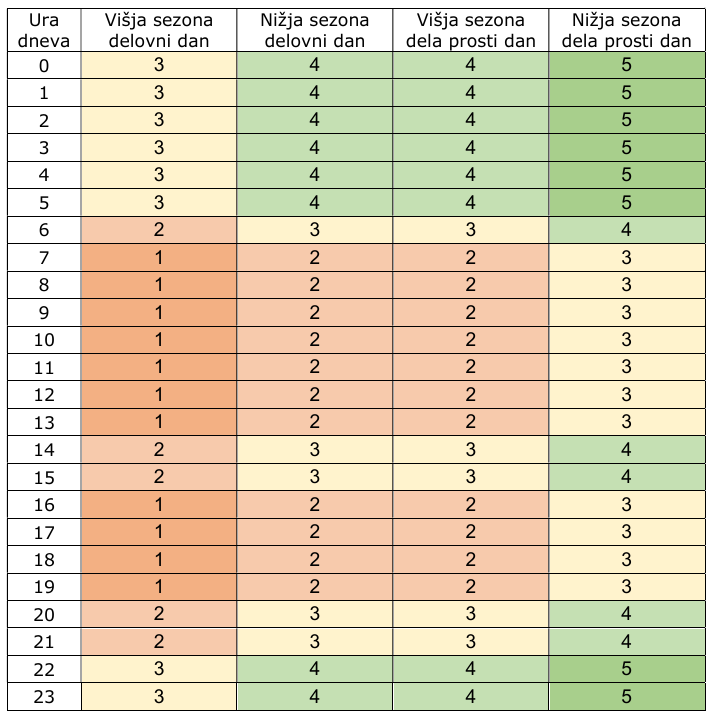
4 tipični dnevi
Do sedaj smo imeli dva tipa dni: delovnike in vikende oz. praznike. Med delovniki je bila višja tarifa med 6h in 22h, v nočnem času pa manjša tarifa. Za vikend in praznike je bila ves dan manjša tarifa.
Po novem bomo imeli bolj razčlenjen čas v dnevu, tako da bo tudi za vikend razlika med dnevnim in nočnim časom. Vseh tarif bo 5, a se bodo znotraj posameznega dne pojavljale zgolj tri. Prav tako se bosta pojavili tudi dve sezoni: višja oz. zimska je v veljavi novembra, decembra, januarja in februarja, in nižja oz. "poletna", ki je v veljavi preostali čas.
Če vse to nekoliko poenostavimo, dobimo 4 tipične dni, ki se bodo lahko v letu pojavljali odvisno od dneva v tednu in meseca v letu.
Podroben pogled pokaže, da se stvar še nekoliko bolj poenostavi, saj je zimska vikend tarifa enaka tarifi poletnega delovnika.
Obračunavanje obračunske moči po izmerjeni najvišji moči
Pomembna novost bo, da se obračunska moč ne bo več plačevala glede na varovalke, ampak po izmerjenem odjemu. Temu se reče dogovorjena moč, saj jo uporabnik dogovori z distributerjem, ob priklopu večjega porabnika, npr. električnega štedilnika, toplotne črpalke ali električnega avtomobila pa bo smiselno zvišanje dogovorjene moči.
Za osnovo dogovorjene moči se predlaga povprečje treh najvišjih konic porabe v 15 minutnem intervalu. Za nekoga, ki nima večjih porabnikov, bo to ugodnost, saj bo zdaj lahko plačeval manjšo obračunsko moč.
Priključnih moči je več
Obračunska moč se dogovarja za vsako izmed petih tarif posebej, pri čemer se predvideva, da imajo cenejše tarife višjo priključno moč. Za prvo in najdražjo tarifo je za trifazni gospodinjski odjem minimalno 3,5kW, za enofazni gospodinjski odjem pa minimalno 2kW.
Obračunavanje presežne moči
Ker bi vsakdo želel plačevati čim manj obračunske moči, je v spodbudo temu, da se obračunska moč nastavi na realno vrednost, uvedeno obračunavanje presežne obračunske moči po višji postavki kot običajno.
Presežna moč se bo na začetku obračunavala po nižji ceni, da se vsi skupaj privadimo na nov sistem, končno ceno pa bo dosegla leta 2028.
Poskusni izračuni
V prihodnjih mesecih bodo na položnici tudi izračuni kako bi izgledal obračun po novem tarifnem sistemu, da se lahko uporabniki seznanimo s spremembo, preden do nje zares pride.
Ali moram varčevati z elektriko na račun udobja?
Načeloma ne. Minimalna priključna moč 3,5kW na trifaznem odjemnem mestu zadošča za večino stvari, ki jih človek vklaplja ob dnevnih opravilih. Na enofaznem odjemnem mestu je minimum obračunske moči 2kW, kar je zelo malo in bo večina imela večjo priključno moč.
Da dogovorjene moči ne presežete, vsekakor pomaga, da sočasno ne poganjate veliko močnih porabnikov. Med močne porabnike spadajo predvsem grelci, npr. pečica, kuhališče, kotliček za segrevanje vode, pralni stroj (prvih 15 minut programa), sušilni stroj, in podobni.
Priložnosti za zniževanje odjema v času višje tarife
Ob predvidevanju, da bo tarifa 1 precej draga, nov tarifni sistem do neke mere spodbuja rabo energije izven konic porabe.
Manjši del porabe predstavljajo ročno upravljani porabniki, kamor sodijo npr. pralni, pomivalni, in sušilni stroj, ki začnejo z delom, ko jih prižgemo. Dobro bi bilo, da se te naprave uporablja izven konice porabe, torej ob nižji tarifi. Vsi danes dobavljivi modeli omogočajo časovno zakasnitev začetka programa, kar lahko pomaga pri zamiku.
Bistveno večjo fleksibilnost omogočajo določeni zelo specifični porabniki, ki lahko s pravilnim dimenzioniranjem in avtomatizacijo omogočajo zamik porabe energije brez zmanjšanja ugodja.
Električni bojler za toplo vodo
Najenostavnejši primer rabe energije izven konične tarife je večji električni boljer za sanitarno toplo vodo, tam od 200 litrov naprej. Tako velike bojlerje se večinoma projektira tako, da zadostujejo za dnevne potrebe gospodinjstva.
Bojlerji so zasnovani tako, da se hladna in topla voda minimalno mešata, tudi kadar se topla voda porablja in v bojler priteka hladna voda. Temu pravimo razslojevanje oz. stratifikacija tople in hladne vode. Zaradi nje ostaja voda na vrhu bojlerja topla zelo dolgo časa, tudi če v vmesnem času porabljamo toplo vodo in je spodnji del bojlerja hladen.
Ker se voda ne meša, postane praktično izvedljivo, da brez spremembe življenjskega sloga in zmanjšanja ugodja vodo segrevamo ob času nižje tarife ali ob delovanju sončne elektrarne, predvsem pa neodvisno od tega kdaj toplo vodo porabljamo.
Električna vozila
Uporabniku električnega vozila je vseeno kdaj se vozilo polni, samo da je ob pričetku uporabe dovolj napolnjeno. Predlagan tarifni sistem bo omogočal večje moči polnjenja izven konične rabe, zlasti ponoči. Praktično vsa električna vozila danes omogočajo nastavitev urnika polnjenja, tako da je lahko vozilo priklopljeno in se začne polniti šele ko nastopi nižja tarifa.
Baterijski hranilnik
Bolj razčlenjena tarifa bo lahko spodbudila koga, da gre v nakup baterijskega hranilnika. Baterijski hranilnik za celodnevno porabo bo verjetno predrag, bi pa lahko bil uporabna naprava v kombinaciji s sončno elektrarno, kjer čez dan priključno moč pokriva energija iz sončne elektrarne, zjutraj in zvečer pa lahko konično porabo pokriva baterijski hranilnik.
Sončna elektrarna
Sončna elektrarna (in tudi druge proizvodne naprave) ne šteje v priključno moč, ki jo plačujejo odjemna mesta. Sončna elektrarna pa omogoča, da lahko odjemno mesto troši višjo moč v primeru da sije sonce, saj je ta energija proizvedena lokalno in za njo ni omrežnine.
Toplotna črpalka
Toplotna črpalka je precej udoben način ogrevanja, žal pa toplotna črpalka sama po sebi ne omogoča časovnega zamika odjema. Časovni zamik je možen v kombinaciji z zalogovnikom za toplo vodo ali z ustrezno izvedbo ogrevalnega sistema, vendar to velja predvsem za novogradnje oz. v primeru celovitejše obnove stanovanjske stavbe. Betonski tlak v talnem gretju lahko namreč deluje tudi kot zalogovnik toplote.
Žal pa je narava ogrevanja taka, da toplotno črpalno uporabljamo predvsem pozimi, v višji sezoni, ko bo tudi cena omrežnine višja.
Vprašanja in odgovori
Ali moram varčevati z energijo na račun udobja?
Načeloma ne, 3,5kW, kolikor je minimum obračunske moči na trifaznem odjemu, je dovolj za večino stvari, ki jih človek pri svojih dnevnih opravilih izvaja.
Kako lahko iz obstoječe priključne moči oz. varovalk izvem kolikšna bo nova priključna moč?
Med obstoječo priključno močjo in novo priključno močjo ni neposredne povezave. Nova obračunska moč je dogovor med lastnikom odjemnega mesta in distribucijskim podjetjem.
Kje lahko vidim novo obračunsko moč?
Nova obračunska moč za prihajajoče leto bo na računu za mesec junij, julij in avgust.
Kaj narediti, če mi obračunska moč, ki mi jo je dodeli distributer, ni všeč?
Če želite obračunsko moč spremeniti, morate do 20. septembra tekočega leta distributerju sporočiti obračunsko moč, ki bi vam ustrezala v naslednjem letu.
Obračunsko moč lahko spremenite tudi naknadno. Do 8. dne v mesecu morate sporočiti željene obračunske moči, da bi te moči začele veljati z naslednjim mesecem.
Obračunsko moč se določa v kW na eno decimalno mesto.
POZOR: Odsvetujem spreminjanje dogovorjene obračunske moči, če niste povsem prepričani, da veste kaj delate. Če spremenite dogovorjeno obračunsko moč, se vam bo presežna moč začela obračunavati v polni višini.
Imam odjemno mesto, ki nima pametnega števca. Kaj se bo zgodilo?
V kolikor nimate pametnega števca, ki bi znal odčitavati 15-minutne intervale porabe energije, boste še naprej plačevali omrežnino po eno- ali dvo-tarifnem sistemu.
Imam sončno elektrarno z 10kW moči. Ali bom moral imeti 10kW priključno moč?
Ne. Omrežnina se plačuje zgolj v smeri proti uporabniku.
Imam sončno elektrarno prek sistema net-meteringa. Ali bom moral plačevati omrežnino?
Za vse, ki so v sistemu net-metering obračunavanja, se količina kilovatnih ur za obračun omrežnine izračuna tako kot do sedaj: izračuna se neto odjem, od tega odjema pa se obračuna omrežnina po enotni tarifi.
Dogovorjena moč se obračunava enako kot za ostale uporabnike. Sončna elektrarna v omrežnino ne šteje, ker je proizvodna naprava.
Kdaj stopi v veljavo nova omrežnina?
Omrežnina po zadnjih informacijah stopi v veljavo 1. julija 2024. (Sprva je bil datum 1. januarja, potem je bila uvedba premaknjena na 1. marec, nazadnje na 1. julij 2024.)
Zdravstveno tveganje
Radon je v Sloveniji zapostavljena in slabo poznana nevarnost za zdravje. Poglavitni problem radona je, da njegova pojavnost viša tveganje za nastanek pljučnega raka. Radon je radioaktiven in razpade na druge prav tako radioaktivne elemente, ki pa niso plini, ampak trdni delci, ki se človeku usedejo v pljuča. Tam sevajo in če je koncentracija radona zares visoka, precej povišajo tveganje za nastanek pljučnega raka. Radon povzroči okrog 9% pljučnih rakov in je za kajenjem drugi najpogostejši povzročitelj pljučnega raka.
Količina radona se meri v Becquerelih na kubični meter, Bq/m³. Povišanje iz 0Bq/m³ nad 100Bq/m³ poveča verjetnost za nastanek pljučnega raka za 16%, povišanje iz 0Bq/m³ na 600Bq/m³ pa verjetnost za nastanek pljučnega raka podvoji.
V tujini so smernice, da mora biti koncentracija radona pod 100Bq/m³, medtem ko so v Sloveniji smernice, da ukrepanje ni potrebno dokler je koncentracija pod 300Bq/m³.
Nacionalna raziskava iz leta 2011-2012 je pokazala povprečne koncentracije radona 340Bq/m³ v hladnem obdobju in 158Bq/m³ v toplem obdobju. Posamezne stavbe in tudi posamezne sobe znotraj stavb lahko precej odstopajo med sabo, zato je izvajanje meritev edini način za določitev koncentracij.
Od kje radon prihaja
Radon prehaja iz tal oz. zemlje v zrak. Radon se lahko pojavlja povsod po Sloveniji in ni enostavno vnaprej vedeti ali se bo pojavljal na dotični lokaciji ali ne. Ko pa na zemlji že stoji stavba, je izvajanje popravkov precej težje, če stavba ni bila sprojektirana s sistemom za odvajanje radona.
Sodobne stavbe so bolj zrakotesne in bolje izolirane, višja zrakotesnost pa lahko poveča koncentracijo radona. K povečani koncentraciji lahko pripomore tudi renovacija, npr. menjava oken za novejše, ki bolje tesnijo.
Radon največkrat prodre v stavbo skozi razpoke in špranje v tleh ali skozi preboje temeljne plošče. V ogrevalni sezoni je znotraj stavbe toplejši zrak, ki povzroča vzgon, zato je ob stiku stavbe s tlemi zračni tlak nižji, razlika v tlaku še dodatno spodbuja vdor radona v stavbo.
Protiradonski ukrepi
Osnova protiradonskih ukrepov je nadzorovano prehajanje radona v plast, iz katere ga lahko nadzorovano odvajamo stran od bivalnih prostorov.
Nadzorovano prehajanje radona se običajno doseže tako, da se pod stavbo ustvari zračna prepustna plast. En način, da se to doseže, je nasutje iz dovolj debelega peska in perforiranimi cevmi, ki omogočajo ventilacijo. Če se pokaže, da je koncentracija previsoka, se lahko kasneje enostavno vgradi ventilator, ki aktivno odvaja radon.
Alternativa je v obliki prostora. Pri nas bi to bila npr. klet, v ZDA pa imajo pogosto pod stavbo nekaj prostora, kamor lahko pospravijo različne napeljave. Ta prostor spet lahko aktivno prezračujemo, če se izkaže, da so koncentracije radona prevelike.
Pomembno je, da je nad prezračevano plastjo tudi radonska zapora, npr. bitumenska hidroizolacija z aluminijastim vložkom.
Stanje v Sloveniji
V Sloveniji zaenkrat protiradonska gradnja ni obvezna, zato so ljudje z njo dokaj slabo seznanjeni, tako splošna javnost kot gradbena stroka. Imamo precej dobre smernice, a so zgolj smernice.
Protiradonski sistem je ena izmed tistih zadev, ki jo je trivialno narediti, ko se stavba gradi, če na to pomislimo. Če na to ne mislimo, lahko postane naknadna sanacija precej draga in štorasta. Lahko pa sprejmemo tveganje in živimo v hiši, ki nas hoče ubiti.
Slovenija v javnih stavbah izvaja program sistematičnega pregledovanja in izvajanja meritev radona. Včasih so meritve na videz presenetljive, saj se lahko precej razlikujejo tudi med sosednjimi prostori v stavbi. Po odkritih težavah z radonom so potem pogosto še težave s politično voljo - nekateri nočejo priznati, da je radon res problem - in finančna sredstva za sanacijo.
Zasebni objekti so v teh študijah slabo pokriti. Kot posameznik se lahko v okviru javnega programa postavite v čakalno vrsto za pridobivanje kompleta za merjenje koncentracije radona, ampak je količina teh merjenj omejena na letni ravni. Precej hitreje in enostavneje je, če si posameznik kupi na trgu prosto dostopno napravo za merjenje radona, a te niso najcenejše.
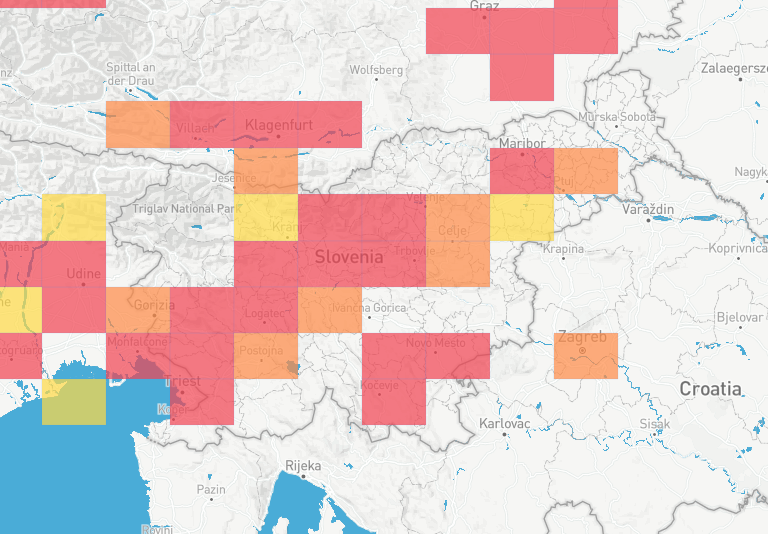
Sam imam izkušnje z Airthings View Plus. Pri tej napravi je zelo jasno, da jo kupci uporabljajo za merjenje radona in jo prenašajo po različnih prostorih, saj omogoča nastavljanje nove lokacije. S spremembo lokacije se prekine časovna vrsta iz katere se potem izdela poročilo o radonu, s tem pa je omogočeno, da se drago napravo bolje izkoristi. Airthings tudi javno objavlja zemljevid pojavnosti radona na podlagi podatkov, ki jih naprave tega proizvajalca zaznavajo.
Povezave:
"Jedna jedina" je zelo dober dokumentarec o jedrskem programu Socialistične federativne republike Jugoslavije in edini jedrski elektrarni, ki je bila postavljena na ozemlju bivše skupne republike.
Vredno ogleda. Jedna jedina na IMDB. Pred časom so dokumentarec predvajali na Hrvaški televiziji, ki je dokumentarec tudi ustvarila, sedaj se ga morda najde na spletu.
Dokumentarec je zelo relevanten za slovensko publiko, ker obravnava jedrski program v Jugoslaviji in vse kar je ta program obrodil, med malo manj dobro stvar šteje rudnik urana Žirovski vrh, ki je sedaj objekt, ki zahteva bolj ali manj stalni monitoring, med dobre stvari pa vsekakor štejeta Institut Jožef Stefan, ki ga je ustanovil Anton Peterlin, in Jedrska elektrarna Krško, edina jedrska elektrarna na svetu v lasti dveh držav. Dokumentarec je miniserija v treh epizodah.
Prva epizoda, spevno naslovljena "Srpom i batom razbit ćemo atom", oriše jugoslovanski jedrski program, za katerega sploh nisem vedel kako ambiciozno je bil zastavljen. Sprva je bil načrt, da bo po celotni Jugoslaviji kar 20 jedrskih elektrarn. Poleg civilne rabe jedrske energije je jugoslovanski jedrski program vseboval tudi vojaško komponento.
Druga epizoda predstavi nesrečo v Černobilu, ki je imela posledice za jedrsko energijo pa tudi na vsakdanje življenje praktično cele Evrope, ter kako smo se spopadali s tem izzivom.
Tretja epizoda obravnava jedrsko elektrarno Krško in operativne težave, ki jih prinaša solastništvo dveh držav, od meddržavnega spora, ki ga je sprožila uredba o preoblikovanju NEK do iskanja rešitev za trajnejšo hrambo jedrskih odpadkov pa tudi jedrskega materiala, ki pravzaprav še niso odpadki, a Hrvaška ne najde dobre rešitve kaj z njim. Zanimivo je videti kako to rešuje Francija, ki večino elektrike pridobivajo iz jedrske energije in ima za jedrske odpadke samostojno agencijo Andra.

Povezave:
V prejšnji objavi sem govoril o tem kako plinski štedilniki puščajo, kjer sem za lastni štedilnik prišel do ocene puščanja v volumnu 4,52 kubične decimetre na dan. Kako natančna je ta ocena?
Natančnost težko ocenim. Plinomer je že odstranjen, tako da nimam priložnosti, da bi ponovil eksperiment, nimam pa tudi opreme, ki bi omogočala natančno merjenje. Lahko pa primerjam svojo oceno z drugimi, ki so bolj znanstveno pristopali k meritvam uhajanja plina.
Stanfordska študija
Odmevna študija, ki so jo izvajali v Kaliforniji na Stanfordu, je obsegala meritve v 53 domovih, kjer so merili koncentracijo metana v zraku v kuhinji. Študija znana predvsem po presenetljivem zaključku, da približno 76% vseh emisij nastane ob tem, ko je štedilnik ugasnjen.
Njihove ugotovitve kažejo, da plinski štedilniki v povprečju v nedelovanju izpuščajo 57,9 mg/h metana. Porazdelitev med štedilniki je precej neenakomerna, saj je iz najslabših 5 štedilnikov uhajalo kar 49% vsega plina. Razen štirih štedilnikov so vsi ostali presegali emisije 10 mg/h. Iz večine štedilnikov in napeljave torej uhaja vsaj nekaj plina, ko štedilnik ni prižgan. Količine uhajanja plina iz štedilnika so bile zelo različne, vendar večina med 10mg/h in nekaj sto mg/h.
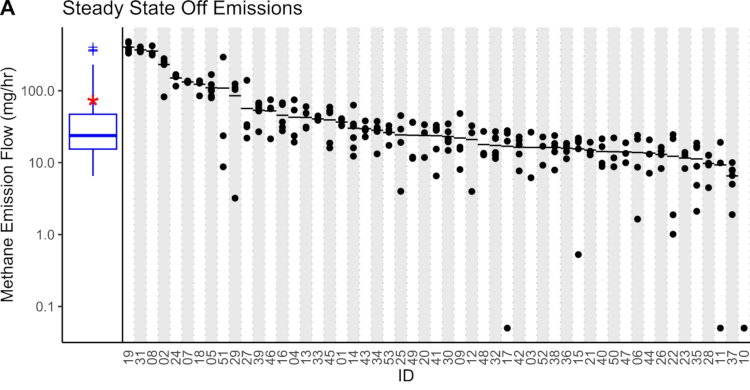
Izpusti pri enkratnem prižigu in ugasnitvi štedilnika so bili izmerjeni pri 45,9mg metana. Izpusti so odvisni od načina prižiganja, najslabši so štedilniki, ki uporabljajo pilotni plamen, a teh pri nas ni.
Študija ni odkrila nobene povezave med izpusti metana in starostjo štedilnika, ceno štedilnika ali prihodki gospodinjstva. Sam bi ob takih rezultatih začel razmišljati, da je zelo pomemben postopek montaže.
Primerjava z mojo oceno
Moj izračun ima v osnovi kaj nekaj problemov. Števec, ki ga uporablja Energetika Ljubljana, ima minimalni nazivni pretok Qmin 0,04m3/h, sam pa sem izmeril 0,000188m3/h, kar je okvirno 200x manj kot Qmin. Števec je certificiran zgolj znotraj območja, ki ga določata Qmin in Qmax. Zunaj tega območja ni preverjan in ima lahko znatno napako.
Prav tako bi lahko na števec vplivalo raztezanje in krčenje plina zaradi spreminjanja atmosferskega tlaka in prehodni pojavi v plinovodu, npr. ko sosedje prižigajo in ugašajo trošila.
Svojo "porabo" ob ugasnjenem štedilniku lahko pretvorim v miligrame. Če za gostoto metana vzamem 0,717kg/Nm3, lahko 4,52dm3/dan pretvorimo v 3,24g/dan metana, oz. na uro je to 135mg/h.
135mg/h zagotovo sodi v velikostni razred, ki so ga izmerili v stanfordski študiji, torej med 10mg/h in nekaj sto mg/h. Izvajalci študije so vseeno imeli precej bolj dodelano metodologijo meritev in boljšo opremo, ki je zares omogočala merjenje zelo nizkih koncentracij plina ne glede na vse ostale spremenljivke.
Če območje med 10mg/h in 100mg/h pretvorimo v kubične decimetre na dan, je to med 0,3347 dm3/dan in 3,347 dm/dan, kar je podobno številki, ki jo je izmeril moj števec.

Imate štedilnik na plin? Pušča vam plin.
Ampak brez panike, to je povsem običajno. Vsaka cev in vsak ventil je priložnost, da se nekaj plina izmuzne. Presenetljivo velika količina plina pa se izmuzne kar iz štedilnika. Ugasnjenega.
To so ugotovile že nekatere druge študije. Je pa novost zame to, da sem se zavedel, da lahko ocenim količino plina, ki mi uhaja iz štedilnika. Do tega pa sem prišel bolj naključno kot načrtno.
Že dlje časa se sicer pripravljam, da bi plinski štedilnik zamenjal. Plin dobivam preko mestnega plinovoda in vsak odjemalec ima na odjemnem mestu plinomer, ki veselo šteje porabo plina. Plinomer je zanimiva naprava, ki nadtlak pretvori v mehansko gibanje, ki premika števec.
Ob koncu meseca sem fotografiral plinomer, da sporočim stanje Energetiki. Poročanje sicer ni obvezno, a v primeru, da stanja števca ne sporočim, dobim obračunano porabo glede na zunanje temperature. Edino trošilo plina v stanovanju je plinski štedilnik. Tega praktično ne uporabljam več, zato je rahlo nadležno, da se plin obračuna, kljub temu, da porabe ni.
Tri dni kasneje sem spet gledal plinomer in ugotovil, da se je stanje na plinomeru spremenilo, čeprav zagotovo nisem uporabljal plinskega štedilnika. Zanimivo!



Koliko plina uhaja
K sreči sem fotodokumentiral stanje plinomera in lahko zdaj naredim odčitek.
Staro stanje 28.2. ob 07:42 je bilo 2095,7938 m3.
Novo stanje 3.3. ob 12:21 je bilo 2095,8092 m3.
Izmerjena razlika je 0,0154 m3.
Razlika v času je 3 dni, 4 ure in 39 minut oz. 76,65 ur.
0,0154 m3 deljeno z 76,65 ur je 0,0002009 m3/h oz. približno 0,201 dm3/h. Na dan plinomer izmeri 4,82 kubične decimetre plina, ki uhaja iz štedilnika.
Ta izračun lahko primerjam s porabo plina za pretekli mesec.
Začetno stanje 31.1. ob 07:38 je bilo 2095,6591 m3. Končno stanje 28.2. ob 07:42 je bilo 2095,7938 m3.
Razlika v plinu je 0,1347 m3. Razlika v času je 28 dni in 4 minute oz. 672 ur.
0,1347 / 672 = 0,0002004 m3/h oz. 0,2004 dm3/h. Na dan plinomer izmeri približno 4,81 kubične decimetre plina. To je presenetljivo podoben rezultat prejšnjemu. Očitno res cel mesec nisem uporabljal plinskega štedilnika.
Ob upoštevanju pretvorbenega faktorja zaradi nadmorske višine 0,93858, je količina fosilnega plina, ki dnevno uhaja, približno 4,52 normne kubične decimetre oz. 0,00452 Nm3.
Kaj to pomeni
Zaradi plinovoda imam nameščen plinomer in sem sploh imel možnost opaziti, da plin uhaja iz štedilnika. V primeru uporabe plina v jeklenki je to težje, saj ni med jeklenko in štedilnikom nobenega števca, sploh pa ne umerjenega.
Količine plina, ki uhajajo iz štedilnika, so tako majhne, da se jih s človeškimi čutili ne voha, ne zazna. Če boste res pozorni in dobesedno tiščali nos v ugasnjen štedilnik, potem morda zavohate značilni "vonj po plinu". Kar zares vohate sicer ni zemeljski plin, ampak dodan plin, ki poskrbi, da lahko uhajanje plina zavohamo.
Z vidika varnosti načeloma take količine ne bi smele biti problematične za neko stanovanje, ki je v redni rabi, kjer se torej odpirajo okna in vrata. Lahko bi se plin začel kopičiti v nevarnih količinah, če bi bili prostori dlje časa zaprti ali če bi se uhajanje povečalo. Če uporabljate jeklenko, je vsekakor smiselno zapreti jeklenko s plinom, če boste za dlje časa odsotni oz. če bojo prostori dlje časa neuporabljani.
Z vidika zdravja vsekakor ni dobro, da vdihavamo ogljikovodike in druge primesi, ki so po plinovodu prišle v hlapni obliki morda namenoma, kot so plini, ki dajejo plinu vonj, kot tudi tisti, ki pridejo z zemeljskim plinom, ker nima smisla popolnoma izločati zgolj metana, če gre za plin, ki je namenjen predvsem sežiganju.
Cenovno je tak izpust tudi pri obstoječih cenah plina zanemarljiv - 12,6 centa na mesec.
Z vidika emisij toplogrednih plinov je plin iz plinovoda predvsem metan, ki je kar 84-krat močnejši toplogredni plin kot CO2. Metan ima pri normalnih pogojih težo 0,717kg/m3, kar pomeni, da vsak dan uide 3,24g metana. To ustreza približno 272g CO2 ekvivalenta emisij. Povedano drugače: plinski štedilnik ždi v hiši, a vsak dan tudi ob neuporabi naredi emisij za nekaj kilometrov vožnje z avtomobilom!
Sledeči izračun je zelo čez palec, tudi zato, ker primerjam mestni plin s plinom iz jeklenke. Če je štedilnik izven uporabe 90% časa, v enem letu uhajanje nanese za 1kg plina. To je približno desetina jeklenke. V prejšnjem stanovanju, kjer sva imela jeklenko, sva eno jeklenko porabila v 10 mesecih. 1kg izpuhtelega plina na 12kg porabljenega bi bilo okrog 8% izgub, kar je veliko.
Za ta plinski štedilnik lahko rečem le, da ne bo več dolgo delal izpustov.
Preberite še naslednjo objavo, primerjavo moje ocene izgub s študijo, ki so jo izvedli na Stanfordu.
Povezave:
- What's inside a gas meter?
- Metan, Wikipedija
- Preračun porabe zemeljskega plina iz m³ v kWh, Energetika Ljubljana
- Your Gas Stove Is Bad for You (And Terrible for the Environment), Popular Mechanics
- Have a gas stove? How to reduce pollution that may harm health, health.harvard.edu
- Even when off, gas stoves can leak benzene concentrations comparable to secondhand smoke, thehill.com
- Kako natančna je ocena uhajanja plina na mojem odjemnem mestu, zejn.net
Referenca: 0073-38/2022
Zadeva: Pripombe k dopolnjenemu predlogu Splošnega akta o spremljanju in nadzoru porabe storitev
Spoštovani!
Predlagam, da se 4. člen predloga Splošnega akta o spremljanju in nadzoru porabe storitev spremeni tako, da se doda 5. odstavek, ki se glasi:
- Mehanizem iz prvega odstavka tega člena mora omogočati spremljanje porabe in blokado storitev dostopa do interneta ločeno v domačem omrežju in ločeno v gostovanju.
Sledi obrazložitev.
Marsikateri uporabnik pred odhodom v tujino nastavi telefon tako, da lahko utemeljeno pričakuje, da telefon ne bo izvajal prenosa podatkov. Tovrstna nastavitev se ponavadi imenuje "mobilni podatki" (ang. "mobile data") ali "podatkovno gostovanje" (ang. "data roaming"). Kljub onemogočeni nastavitvi do prenosa podatkov prihaja in uporabniki smo neprijetno presenečeni, ko nam operaterji zaračunajo storitev, ki smo jo izklopili.
Prenos podatkov se namreč dogaja, a ne po volji uporabnika telefona. LTE oz. 4G omrežje ne deluje brez prenosa podatkov. Kadar koli se telefon poveže na omrežje preko 4G protokola, se vedno vrši tudi prenos podatkov. Uporabniška oprema (telefoni) je vedno povezana na IP omrežje, to je t.i. koncept "always-on IP".
Težava nastaja na več točkah. Pogosto telefon ob klicu preklopi v način 3G, ob koncu klica pa spet preklopi v 4G način. Vsak priklop na 4G lahko vnovič vrši prenos podatkov. Prejemanje nekaterih SMS ali MMS tudi šteje v prenos podatkov. Prav tako obstaja možnost, da telefon sam sicer ne dela podatkovnih prenosov, ampak ker je IP omrežje vedno omogočeno, se lahko vrši podatkovni prenos z omrežja na napravo.
Priklop na 4G omrežje je torej tehnični detajl tehnologije mobilne povezave, ki ga mobilni operaterji zaračunavajo kot prenos uporabniških podatkov, četudi prenos podatkov ni uporabniku nudil nobene končne uporabne vrednosti.
Da bi se izognili odgovornosti mobilni operaterji svojim uporabnikom svetujejo uporabo tehničnega obvoda, in sicer nastavitev telefona, da naj se povezuje največ na 3G omrežje. Tako nastavljen telefon se ne povezuje več na 4G in tudi ne izvaja podatkovnega prenosa, ki bi ga mobilni operaterji obračunali.
Žal pa smo uporabniki soočeni z dejstvom, da mobilni operaterji omrežja 3G izklapljajo in svoje omrežje nadgrajujejo na novejše protokole. V Sloveniji je 3G že izklopil Telekom Slovenije, A1 Slovenija pa namerava to storiti enkrat do konca leta 2024. V ZDA so omrežja 3G že izklopili in ne delujejo več. Časovnice prenehanja delovanja 3G omrežij se razlikujejo, a trendi kažejo, da v prihodnjih letih načrtuje izklope 3G omrežij večina operaterjev, če tega niso že storili.
Poleg izklapljanja 3G omrežij se podpora tem omrežjem umika tudi iz telefonov, saj nekateri novejši telefoni ne omogočajo več preklopa na omrežje 3G. Na zadnjih Apple iPhone napravah je na voljo le še izbira med 4G in 5G.
Mobilni operaterji torej od povprečnih uporabnikov zahtevajo spremembo povsem tehnične nastavitve v nastavitvah telefona. Zahtevajo, da svoj telefon nastavimo na tehnično zastarele protokole, ki jih ti isti operaterji ugašajo. Od nas zahtevajo, da uporabljamo omrežje s slabšo pokritostjo, če pa uporabljamo novejše omrežje, pa smo za to kaznovani.
Uporabniki nismo izbirali tehnologije, ki jo mobilni operaterji uporabljajo, da gradijo svoje omrežje. Operaterji morajo razločevati med podatki, ki končnemu uporabniku tvorijo dodano vrednost in za katere so uporabniki pripravljeni in dolžni plačevati, ter med tistimi, ki so del interne signalizacije mobilnega operaterja in nad katerimi uporabnik nima nadzora.
Za implementacijo funkcije izklopa prenosa podatkov v sklopu standardov, ki urejajo mobilne komunikacije, že obstaja tehnična rešitev, imenovana "PS Data Off". Ta omogoča, da se podatkovni prenos omeji na nivoju omrežja, hkrati pa se ohrani delujoč nabor storitev kot so npr. klici in pošiljanje kratkih sporočil. Ta funkcija zahteva podporo v uporabniški opremi, podporo v mobilnem omrežju, ter podporo na strani domačega operaterja, ki mora SIM podati informacijo o tem katere storitve so izvzete iz prepovedi prenosa podatkov, t.i. "3GPP Data Off Exempt Services". Trenutno žal ni jasno kateri operaterji to funkcijo omogočajo in uporabnik nad tem nima nadzora.
Poleg zaenkrat še delujočega obvoda, torej preklopa na 3G, nekateri operaterji predlagajo blokado mobilnih podatkov, a to blokado (nekateri, vsaj A1) nudijo brez diskriminacije glede na to če se uporabniška naprava prijavlja v domače omrežje ali pa je naprava v gostovanju. Podatkovni prenos, ki se izvaja kljub izklopljenemu podatkovnemu prenosu na telefonu, ni pod nazdorom uporabnika, zato je praviloma to največji vir nepredvidenih in neupravičenih stroškov. Nekateri operaterji samodejno vklopijo "ugodnejše" opcije podatkovnega prenosa, a če je uporabnik predhodno izklopil prenos podatkov, omrežje pa še vedno izvaja prenos podatkov, to pač ni storitev, ki jo je uporabnik naročil in se mu neupravičeno zaračunava nenaročeno storitev, kljub temu, da je uporabnik izvedel vse razumne in tehnično dosegljive ukrepe za onemogočenje prenosa podatkov.
Poudaril bi, da se v dopolnjenem predlogu Splošnega akta o spremljanju in nadzoru porabe storitev ne razlikuje med podatkovnimi prenosi, ki se izvajajo med uporabniško opremo in omrežjem, ter med dostopom do javnega podatkovnega omrežja oz. interneta. V drugem odstavku 5. člena se "prenos podatkov" celo izrecno pojavi kot sopomenka za "dostop do interneta", kar, kot je pojasnjeno zgoraj, v 4G/LTE omrežju in novejših ni enostavna sopomenka.
Ustrezna ureditev bi razlikovala med podatkovnimi prenosi, ki predstavljajo za uporabnika dodano storitev ter tistimi, ki služijo zgolj delovanju omrežja oz. podpori drugim storitvam, npr. vzpostavitvi klica.
Alternativna ureditev, ki bi razrešila to težavo, je, da operater omogoči uporabnikom, da lahko sami ločeno onemogočajo storitve v domačem omrežju in storitve v gostovanju, zlasti da lahko ločeno onemogočajo dostop do interneta v domačem omrežju in ločeno v tujini. V 4. členu predloga Splošnega akta o spremljanju in nadzoru porabe storitev je opredeljen mehanizem za spremljanje in nadzor porabe, ki mora zato nujno zagotoviti, da se izklop dostopa do interneta obravnava ločeno za domače omrežje in ločeno za gostovanje.
Namen tega je, da se odgovornost za podatkovne prenose, ki so potrebni pri vzpostavitvi, izvajanju in zaključku javne medosebne komunikacije, prenese nazaj na operaterja omrežja. S tem se operaterje spodbudi, da se končnemu uporabniku storitev medosebne komunikacije obračunava celovito, in ne da se obračunava dvojno poleg npr. storitve govorne komunikacije še podatkovni prenos, ki je bistven del te govorne storitve in je hkrati povsem izven nadzora končnega uporabnika.
V upanju, da uvidite utemeljenost dopolnitve vas lepo pozdravljam.
Povezave:
- Dopolnjen predlog Splošnega akta o spremljanju in nadzoru porabe storitev, AKOS
- Nasvet A1, da si naj pred odhodom v tujino telefon nastavimo na 3G ali da naj uveljavimo blokado podatkov
- Nasvet Telekoma, da naj si pred odhodom v tujino telefon nastavimo na 3G
- Novica Telekoma o izklopu 3G omrežja
- Novica o izklapljanju 3G omrežij