Prosti podatki so pogosto opevani kot zelo uporabna reč, vendar je očitno, da marsikdo te uporabnosti ne prepozna. Pa poglejmo zakaj so podatki, ki so dostopni v tabelarični obliki, lahko uporabni.
Recimo, da si na primer želimo ogledat kak film na Ljubljanskem mednarodnem filmskem festivalu. Izbire je preveč, zato je nujno narediti selekcijo. Kako to narediti? Ročni način bi bil, da z miško klikaš po seznamu, prebereš opise, morda pogledaš še video in si sproti ustvariš zaznamke. Če se ti da še malenkost bolj potrudit (ali če je opis premalo sporočilen), pogledaš še na IMDB za oceno. Na podlagi teh zaznamkov se potem odločiš za ožji izbor.
Malo manj ročni način je z uporabo računalniškega programa. Program festivala žal ni na voljo v tabelarični obliki, kar pomeni, da bo s pridobivanjem podatkov nekoliko več dela. Podatke je potrebno izvleči iz kode spletne strani.
Za programiranje bom uporabil prost programski jezik Python. Najprej preberimo kodo spletne strani. Da bo program "razumel" kodo, bomo uporabili dodatno knjižnico lxml. Sam sem uporabil Python 2.7 in lxml 2.3.
#!/usr/bin/python # nalozimo knjiznico import lxml.html # naslov, kjer se nahaja program festivala root = 'http://www.liffe.si/program/abc-seznam/' # preberimo spletno stran h = lxml.html.parse(root).getroot() h.make_links_absolute(root)
Zdaj smo prebrali spletno stran. Ta se nahaja v spremenljivki h. Iz naložene spletne strani je zdaj potrebno dobiti zapise o posameznem filmu. Koda spletne strani ima obliko drevesa. S plezanjem po drevesni strukturi izberemo delčke strani, ki nas zanimajo. Če izberemo vse vrstice, bomo lahko prebrali vse filme.
# ... koda se nadaljuje od zgoraj
# zanimajo nas zapisi v tabeli filmov
# s spodnjim ukazom poiščemo vrstice (tr) znotraj tabele (table),
# ki se nahaja znotraj obrazca (form), katerega atribut "id" je "pluginAppForm"
trs = h.xpath('//form[@id="pluginAppForm"]//table/tr')
# seznam za shranjevanje zapisov
filmi = []
# sprehodimo se po vseh vrsticah
for tr in trs:
# znotraj vrstice tr izberemo polja
tds = tr.xpath('.//td')
# iz vsakega polja poberemo besedilo
teksti = []
for c in tds:
teksti = teksti + c.xpath('.//text()')
# ker so v nekaterih vrsticah črte med črkami abecede,
# je potrebno te vrstice ignorirati, kar naredimo tu
if len(teksti) != 6:
continue
# izpisimo informacije, ki jih imamo sedaj
print teksti
# dodajmo informacije o filmu v seznam filmov
filmi.append(teksti)
Datoteka: liffe1.py
Zdaj smo uspeli prebrati kar nekaj informacij o filmih, ki se bodo na festivalu predvajali. Slovenski naslov, naslov v izvirniku, država in leto, režiserja, jezik in kategorijo, v katero je na festivalu umeščen.
Ker bi želeli to prebrati kot preglednico, se nam splača to shraniti v zapis, ki ga bo prebavil Calc ali Excel. Najenostavnejši je CSV oz. z vejico ločena polja.
# informacije o filmih so shranjene v spremenljivki "filmi"
# nalozimo modul csv
import csv
# odprimo novo datoteko liffe22.csv, v katero bomo podatke shranili
wr = csv.writer(open('liffe22.csv','w'))
# vpisimo naslove stolpcev
wr.writerow(['Naslov', 'Originalni naslov', 'Drzava, Leto', 'Rezija', 'Jezik', 'Kategorija'])
# vsak film vpisemo v datoteko
for f in filmi:
polja = []
for p in f:
polja.append(p.encode('utf-8'))
wr.writerow(polja)
Datoteka: liffe2.py
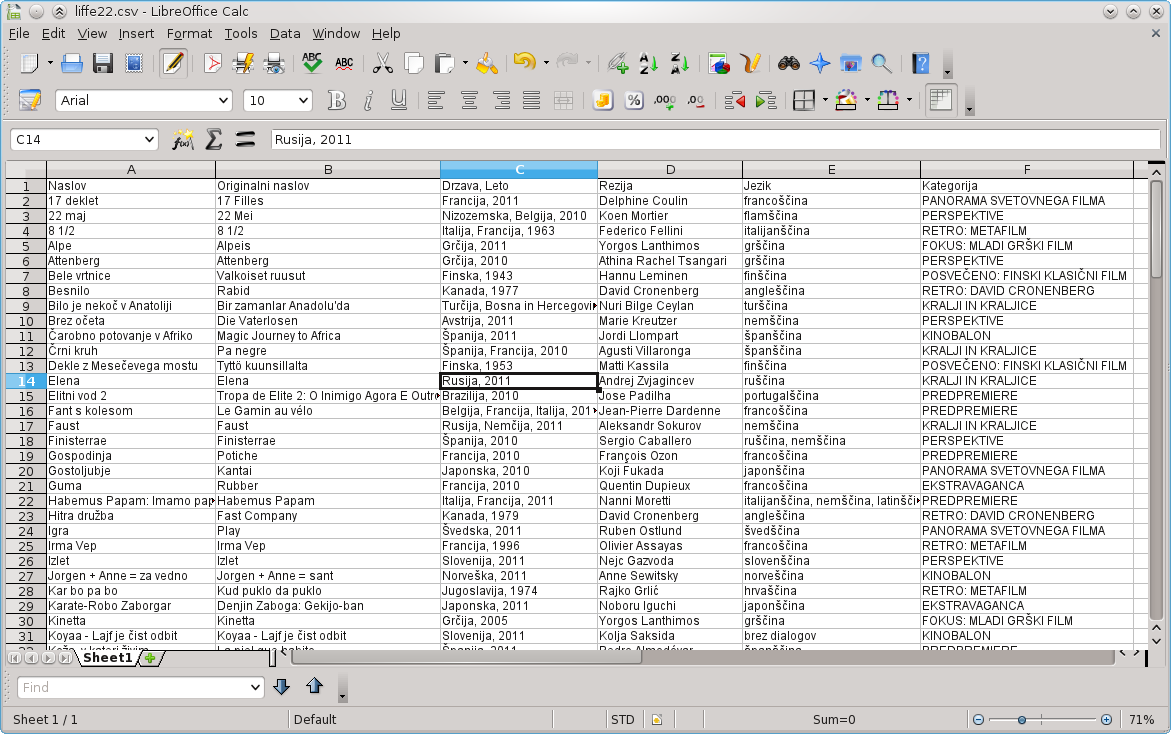
Če sedaj datoteko liffe22.csv odpremo z Excelom oz. Calcom, bomo videli nekaj podobnega spodnji sliki:
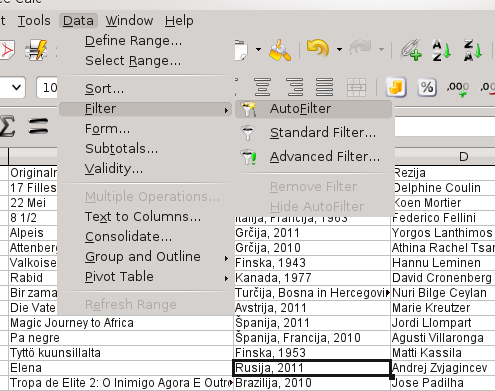
Z uporabo preglednice lahko potem izvajamo bolj zanimive stvari, npr. filtriramo. Najprej uporabimo AutoFilter:
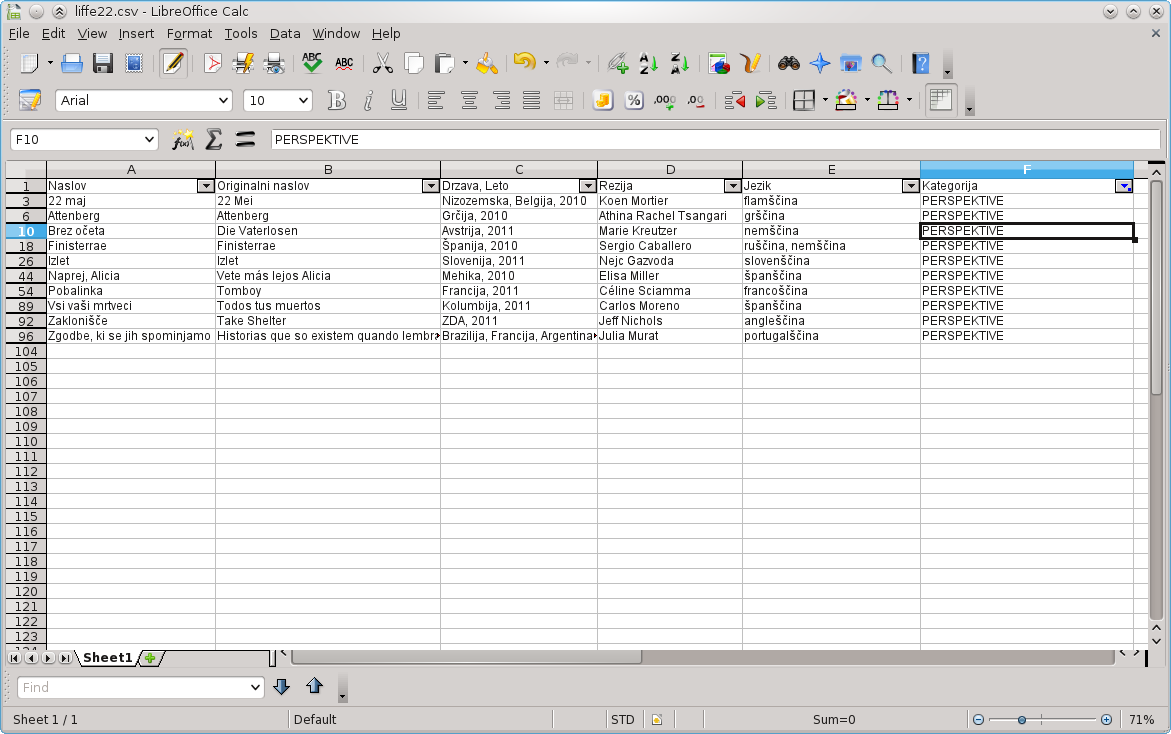
Če sedaj označimo, da želimo pregledati le perspektive, potem vidimo nekaj podobnega:
Če želimo pregledovati po letniku filma, pa naletimo na težavo, saj je leto združeno z državo. Zato moramo naš program malo popraviti:
...
if len(teksti) != 6:
continue
# locimo drzavo in leto v dve polji
drzava_leto = teksti[2].rsplit(', ', 1)
# vkomponiramo novi polji
teksti = teksti[:2] + drzava_leto + teksti[3:]
# izpisimo informacije, ki jih imamo sedaj
print teksti
...
# vpisimo naslove stolpcev
wr.writerow(['Naslov', 'Originalni naslov', 'Drzava', 'Leto', 'Rezija', 'Jezik', 'Kategorija'])
...
Datoteka: liffe3.py
Skoraj perfektno, sedaj lahko filtriramo tudi po letu izida.
Sedaj imamo podatke v tabelarični obliki v zapisu, ki ga lahko uporabimo, da podatke obogatimo še s čim drugim... na primer s podatki, ki so v IMDB. IMDB ima v bazi povprečje ocen filma, ki so jih filmu prisodili uporabniki, kar je včasih kar dober indikator. Dodajmo še to:
# nalozimo knjiznice
import lxml.html
import json
import urllib
...
# locimo drzavo in leto v dve polji
drzava_leto = teksti[2].rsplit(', ', 1)
# dodajmo še ocene in žanr iz IMDB
# sestavimo url
orig_naslov = urllib.quote(unicode(teksti[1]).encode('utf-8'))
url = 'http://www.imdbapi.com/?t=%s&y=%s' % (orig_naslov, drzava_leto[1])
# prenesimo url
imdb_text = urllib.urlopen(url).read()
# nalozimo zapis v program
imdb = json.loads(imdb_text)
# preberemo oceno
imdb_ocena = imdb.get('Rating', '')
imdb_zanr = imdb.get('Genre', '')
# vkomponiramo nova polja
teksti = teksti[:2] + drzava_leto + teksti[3:] + [imdb_ocena, imdb_zanr]
...
wr.writerow(['Naslov', 'Originalni naslov', 'Drzava', 'Leto', 'Rezija', 'Jezik', 'Kategorija', 'IMDB ocena', 'IMDB zanr'])
...
Datoteki: liffe4.py in liffe22.csv
Tako dobljeno CSV datoteko zdaj ponovno odpremo s Calcom oz. Excelom, ponovno uporabimo AutoFilter in podatke posortiramo padajoče po IMDB oceni (Data -> Sort). Tako dobimo dobro informacijo če je določen film vreden ogleda ali vsi pred njim bežijo.
Seveda teh ocen ni nujno upoštevat. Liffe je super priložnost, da si človek ogleda kak tretji film, ki ga brez festivala sploh ne bi opazil.